
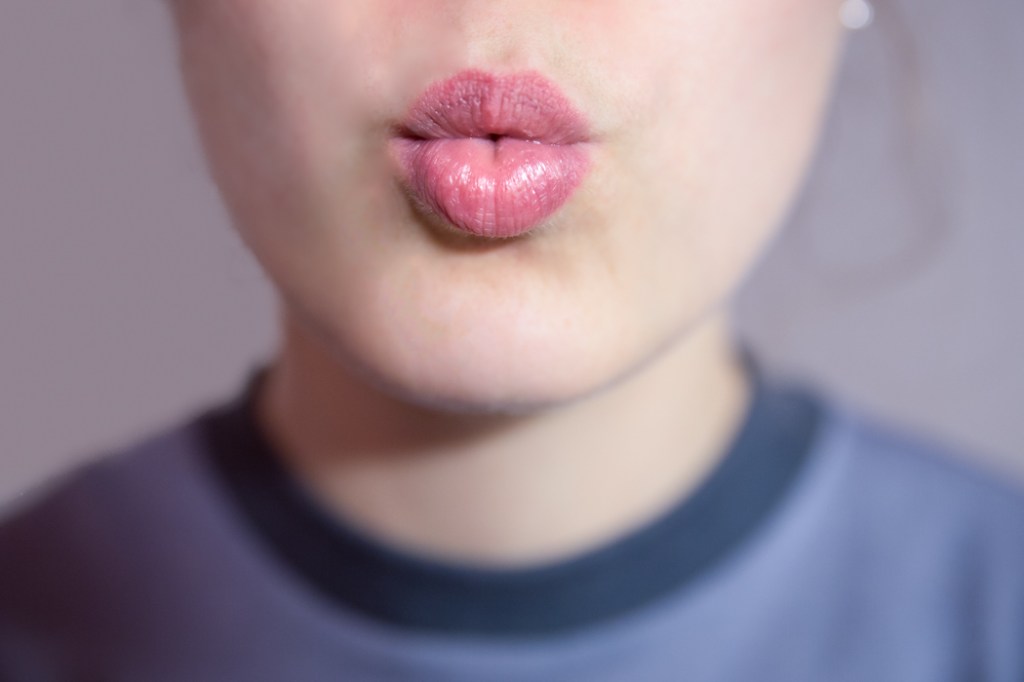
Norsk har hele 18 vokaler (9 korte og 9 lange), en mengde få andre språk kan matche. Når noen skal lære seg norsk, vil man mest sannsynlig møte dette systemet med et mindre vokalsystem enn det norske. Utenlandske studenter står dermed foran en stor oppgave: De må lage plass til de nye vokalene i et fiks ferdig system, og det fører til at de må endre oppfattelsen på de lydene de allerede kan. Selv om de fleste vil være enig i at uttaleundervisning er viktig for norskopplæringen, er det mye som tyder på at lærere har problemer med å finne tid til dette i klasserommet. Hvordan kan man drive god og meningsfull uttaleundervisning for norskinnlærere?
Av Cecilie Slinning Knudsen, universitetslektor i norsk for utlendinger ved NTNU
Forestill deg at du har et intrikat filter i hjernen, et filter som hver eneste ytring du hører, blir silt gjennom. Etter å ha tilegnet deg morsmålet ditt er dette filteret tilpasset lynrask analyse av dette språket. Når du senere møter et nytt språk, antar mange forskere at vi oppfatter dette språket gjennom morsmålsfilteret. Et eksempel er oppfattelsen av th-lyden (/θ/), som finnes i engelske thanks. Når en nordmann hører denne lyden, vil han filtrere den gjennom det norske filteret. Siden /θ/ ikke eksisterer i norsk, kan nordmannen identifisere /t/ som den nærmeste norske lyden.
Når du skal lære deg et nytt språk, vil du forsøke å skape et nytt filter for det nye språket. I dette filteret trenger du nye kategorier, selv for de lydene som ligner dem du allerede har i morsmålet ditt. Det betyr at selv om både morsmålet og det nye språket for eksempel har en kategori kalt /y/, vil du danne en /y/-kategori per språk. Grunnen til at vi gjør dette, er at ulike kategorier, og da spesielt ulike vokalkategorier, sjelden deler nøyaktig de samme akustiske egenskapene. En vokal er ikke bare ETT lydsignal. Hver vokal har og er en kategori som inneholder flere lydsignaler.
I masteroppgaven min sammenlignet jeg hvordan vokaler oppfattes forskjellig av folk med ulike morsmål. Jeg studerte både kategoriene til folk med norsk som morsmål (L1 NO) og folk med mandarin (en kinesisk dialektgruppe) som morsmål (L1 CM) og kategoriene til sistnevnte gruppe når de lærer seg norsk (L2 NO). Alle mennesker kan i utgangspunktet oppfatte de samme lydene uansett språk. Dette spekteret kalles et akustisk rom. Hvilke vokaler som oppfattes hvor, varierer imidlertid fra morsmål til morsmål. Vi ser hvor forskjellig personene med morsmålene norsk og kinesisk oppfattet vokalene o (/u/), u (/ʉ/) og y (/y/).
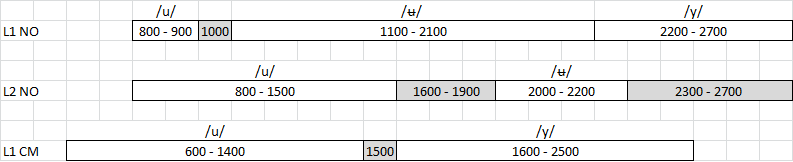
Hvis vi ser nærmere på u-kategorien, ser vi at den lyden spenner fra 1100 til 2100 Hz hos de med norsk som morsmål (L1 NO). Hos kineserne (L1 CM) derimot finnes ikke en u-kategori. Dette skyldes at denne lyden ikke eksisterer som egen kategori i mandarin. Det akustiske rommet til den norske u-lyden er dermed fordelt mellom o og y hos disse informantene. De vil derfor oppfatte den norske u-lyden som enten o eller y. Hos kineserne som lærer norsk (L2 NO), ser vi at de har blitt oppmerksomme på u-kategorien, men at grensene ikke samsvarer helt med morsmålsnorsk ennå, og det er fremdeles noe behov for justering.
Så hvordan endres disse grensene når du lærer et nytt språk? La oss se på et litt forenklet eksempel: En venn kommer til deg og sier at sønnen hennes har fått lus, men du hører at sønnen har fått lys. Dette gir ikke mening, så du korrigerer forståelsen din til det som gir mening, nemlig lus. Vi bruker slik positiv og negativ tilbakemelding fra omgivelsene for å endre kategorigrenser, basert på betydningen av ord. Dette kalles meningsdrevet læring (meaning-driven learning).

La oss nå se på et konkret undervisningsopplegg for innlæring av forskjellen mellom i og y basert på kunnskapen ovenfor. Dette opplegget finnes på nettsiden www.uttale.no. Opplegget begynner med å gi innlærerne knagger å henge lydene på. Lydene blir presentert sammen med et bilde som på en eller annen måte gir assosiasjoner til lyden. For y er det noen som kysser, og for i er det et smil. Det var da jeg så studenter imitere dette flere uker etterpå for å forklare medstudenter hvilke lyder de mente, at jeg virkelig fikk tro på at dette opplegget hadde noe for seg. Jeg kan også nå bare lage en kysselyd for å minne studenter på lyden y mens de snakker, i stedet for å avbryte og korrigere uttalen.
Deretter presenteres lydene i ord som utgjør minimale par, slik som ski og sky, for å gjøre studentene bevisste på forskjellene i uttale. På denne måten lærer de at det finnes et skille i betydning mellom slike ord, selv om de kanskje ennå ikke hører en forskjell mellom lydene. Nå vet de at det skal veldig lite til for å ha to forskjellige ord i norsk, og at denne forskjellen, som noen ikke kan skille fra hverandre ennå, er viktig.
Deretter følger automatiseringen, altså ren øving til man kan det! I en automatiseringsprosess vil umiddelbar tilbakemelding på din oppfattelse og uttale være optimal, en såkalt feildrevet læring (error-driven learning). I dette konkrete undervisningsopplegget får studentene hver sin liste med forskjellige ord som inneholder de to lydkategoriene som er i fokus denne økta, for eksempel y og i. De leser ordene til hverandre, og den andre skriver dem ned.

Neste viktige komponent er hjemmearbeid i form av flashcards og staveoppgaver med lyd. Jeg benytter meg her av Quizlet. Studentene kan høre og gjette på ordene. De får så umiddelbar tilbakemelding på stavingen av ordet og ny innputt av lyd når de «snur» flashcardene, som vist i figuren under.
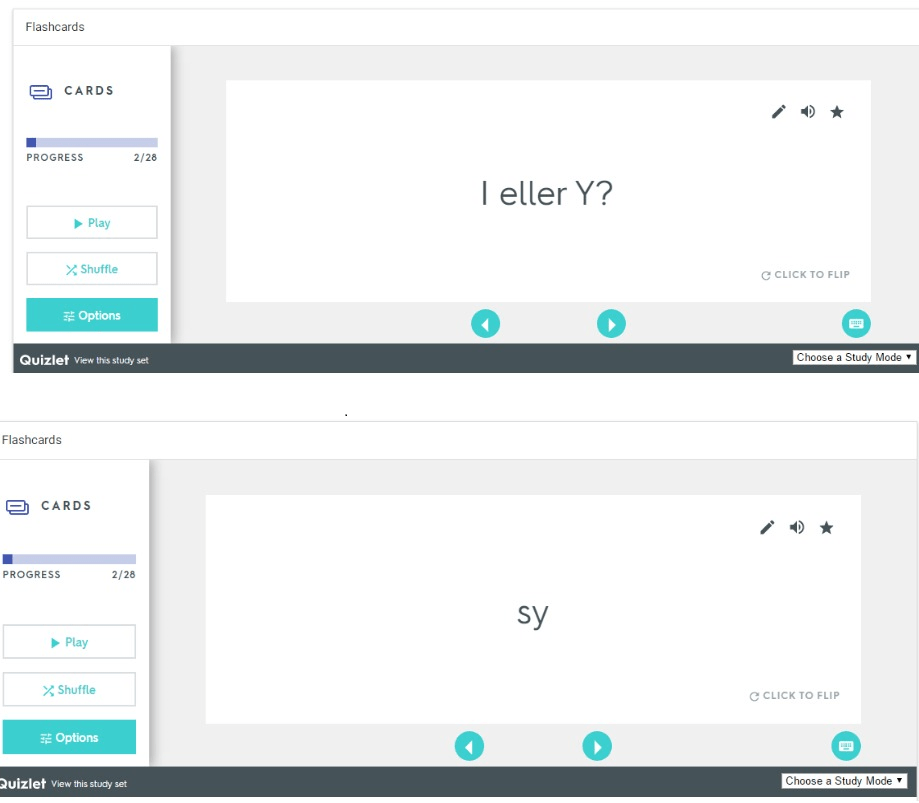
Siste del av hjemmearbeidet er å øve på staving av ord. Studentene lytter og skriver ned ordet de hører, og de får straks tilbakemelding på om de har skrevet riktig. Ordene er de samme som de ordene de nettopp øvde på gjennom flashcardene.
Ved retur til skolen, kanskje allerede neste dag, «sjekkes» oppfattelsen til studentene via en runde Kahoot!. Fordelen med Kahoot! er at studenter flest synes det er en morsom aktivitet, og dette kan øke deltakelsen både ved selve Kahoot!-en og repetisjonen hjemme. Her bør ordene gjentas i plenum for å få en repetisjon av uttalen. Det er ikke alltid man har mulighet eller tid til å benytte seg av Kahoot! Den første gangen jeg prøvde ut denne metoden, delte jeg ut lapper med lydene til deltakerne. Jeg sa et ord, og de holdt opp lappen med den lyden de mente at de hørte. Dette fungerte utmerket! Lappene lages enkelt selv ved å brette et A4-ark i to og skrive for eksempel i på ene siden og y på andre siden.
Dette undervisningsopplegget er under utvikling og utprøving, men studenter fra alle trinn, spor og nivå virker å finne det interessant og nyttig. Mitt håp er at undervisningen som blir presentert her, fra www.uttale.no, skal være tilstrekkelig effektiv og engasjerende til at det blir funnet tid hos både undervisere og studenter. Lykke til, og ha det moro!
Vil du vite mer?
På www.uttale.no er hele undervisningsopplegget forklart, steg for steg. Her finner lærere PowerPoint-presentasjoner for bevisstgjøring, studentdiktater og linker til Kahoot!-er som de kan gjennomføre i klasserommet. Studenter får tilgang til Quizlet-er, direkte integrert i nettsiden. Siden er under utvikling, og nytt innhold blir lagt ut fortløpende. Sidens Facebook-side finner du her.
Mer om teorien bak opplegget kan du lese om i masteroppgaven min, Perceptual Acquisition of Norwegian Close Rounded Vowels by Mandarin Chinese Learners of Norwegian fra 2013.
For å vite mer om meaning-driven learning, kan du lese denne artikkelen av van Leussen og Escudero (2015).
På NTNUs ”Computer-Assisted Listening & Speaking Tutor” – CALST, som du finner her kan man lære et basisvokabular på 1000 ord og uttrykk, samt øve på spesifikke lydkontraster.
